Welcome to FastVideo¶
FastVideo is a unified inference and post-training framework for accelerated video generation.
FastVideo is an inference and post-training framework for diffusion models. It features an end-to-end unified pipeline for accelerating diffusion models, starting from data preprocessing to model training, finetuning, distillation, and inference. FastVideo is designed to be modular and extensible, allowing users to easily add new optimizations and techniques. Whether it is training-free optimizations or post-training optimizations, FastVideo has you covered.
Key Features¶
FastVideo has the following features:
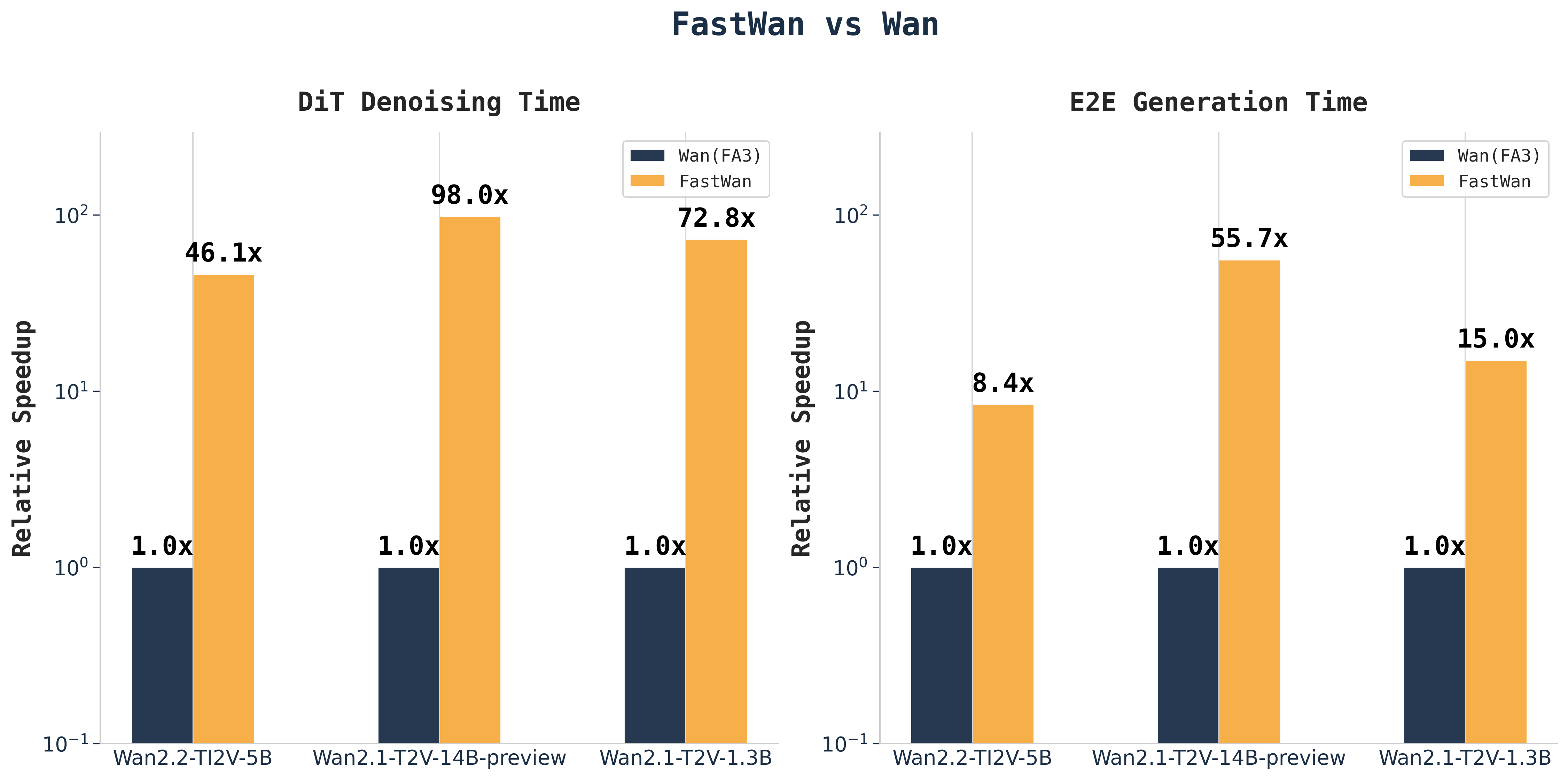
- State-of-the-art performance optimizations for inference
- E2E post-training support
- Data preprocessing pipeline for video data
- Sparse distillation for Wan2.1 and Wan2.2 using Video Sparse Attention and Distribution Matching Distillation
- Support full finetuning and LoRA finetuning for state-of-the-art open video DiTs.
- Scalable training with FSDP2, sequence parallelism, and selective activation checkpointing, with near linear scaling to 64 GPUs.
Documentation¶
Welcome to FastVideo! This documentation will help you get started with our unified inference and post-training framework for accelerated video generation.
Use the navigation menu on the left to explore different sections:
- Getting Started: Installation and quick start guides
- Inference: Learn how to use FastVideo for video generation
- Training: Data preprocessing and fine-tuning workflows
- Distillation: Post-training optimization techniques
- Sliding Tile Attention: Advanced attention mechanisms
- Video Sparse Attention: Efficient attention for video models
- Design: Framework architecture and design principles
- Developer Guide: Contributing and development setup
- API Reference: Complete API documentation