CAD: Disaggregating Core Attention for Efficient Long-context Language Model TrainingDecember 17, 2025Yonghao Zhuang*, Junda Chen*, Bo Pang, Yi Gu, Yibo Zhu, Yimin Jiang, Ion Stoica, Eric Xing, Hao Zhang
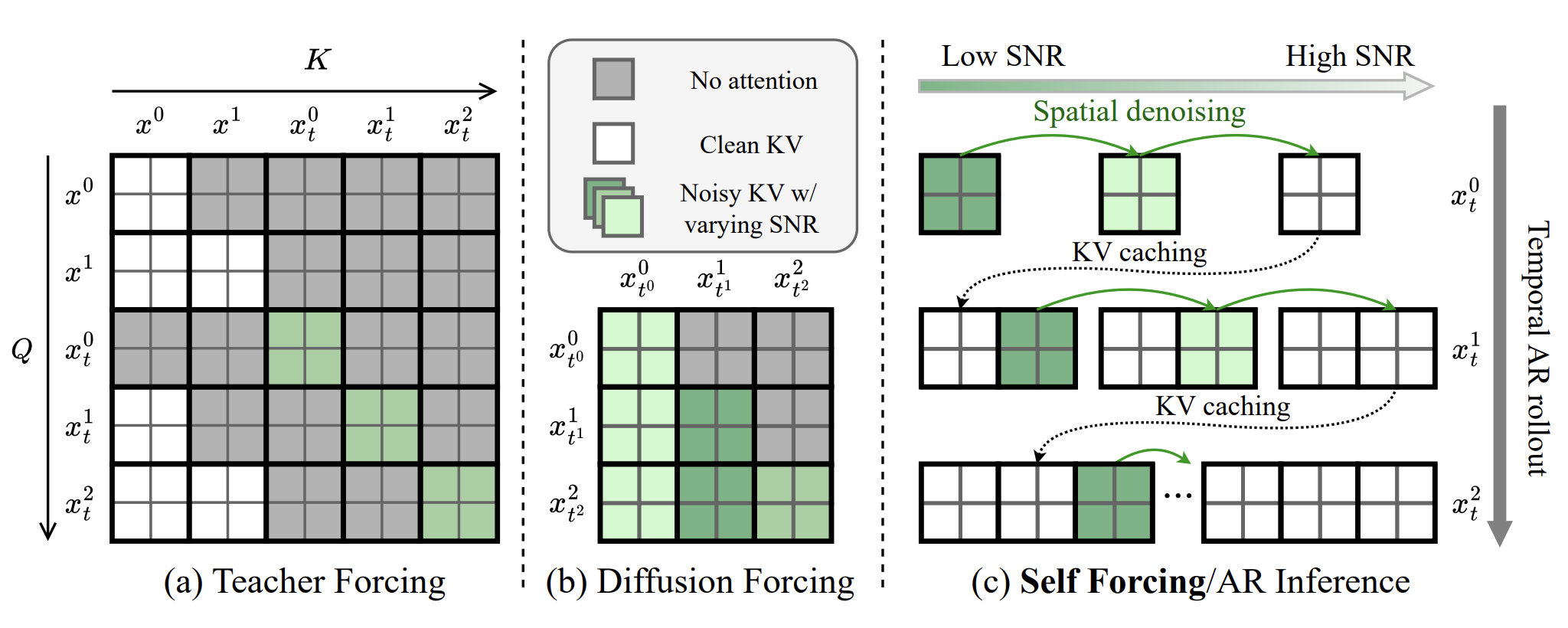
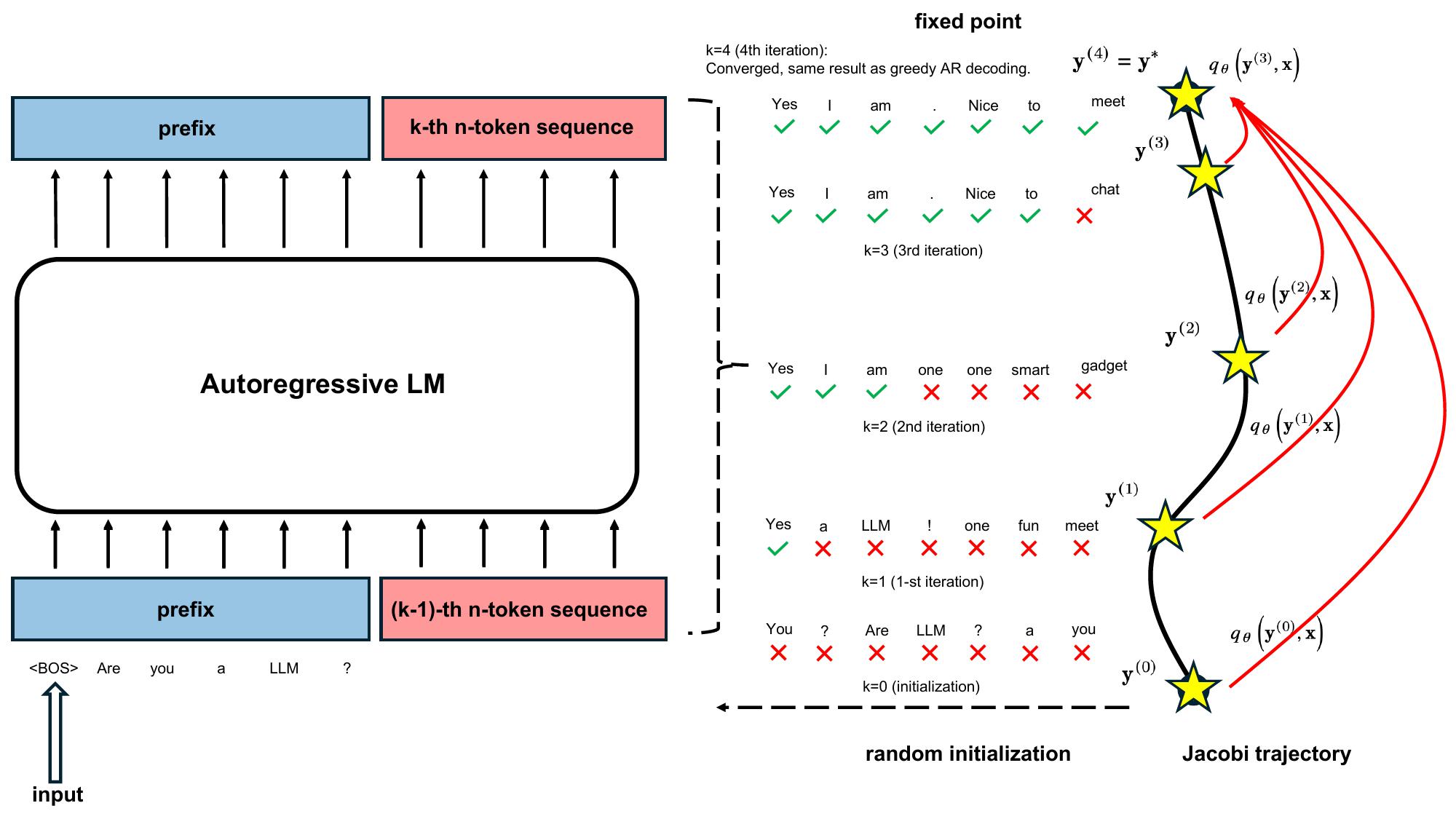
Fast and Accurate Causal Parallel Decoding using Jacobi ForcingDecember 16, 2025Lanxiang Hu*, Siqi Kou*, Yichao Fu, Samyam Rajbhandari, Tajana Rosing, Yuxiong He, Zhijie Deng, Hao Zhang
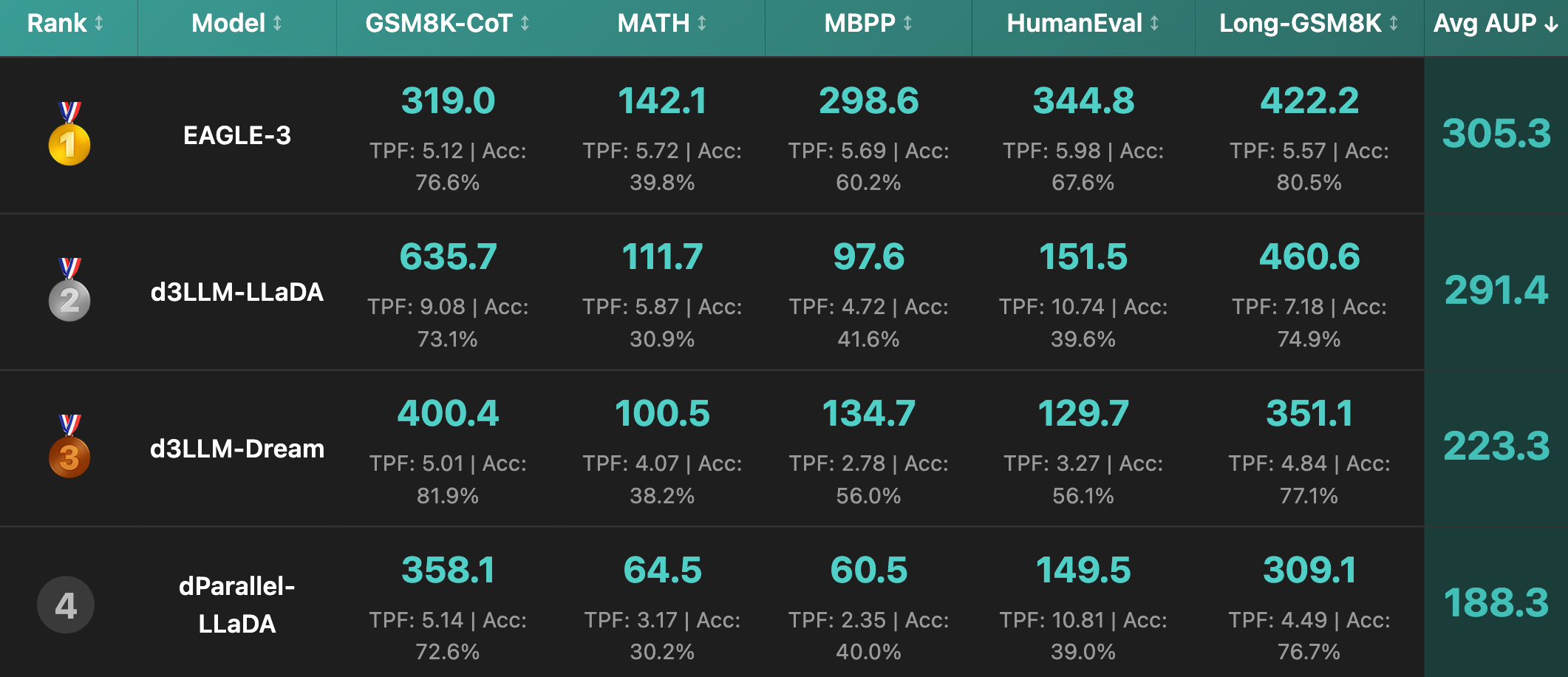
AUP: when Accuracy Meets Parallelism in Diffusion Language ModelsDecember 10, 2025Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, Hao Zhang
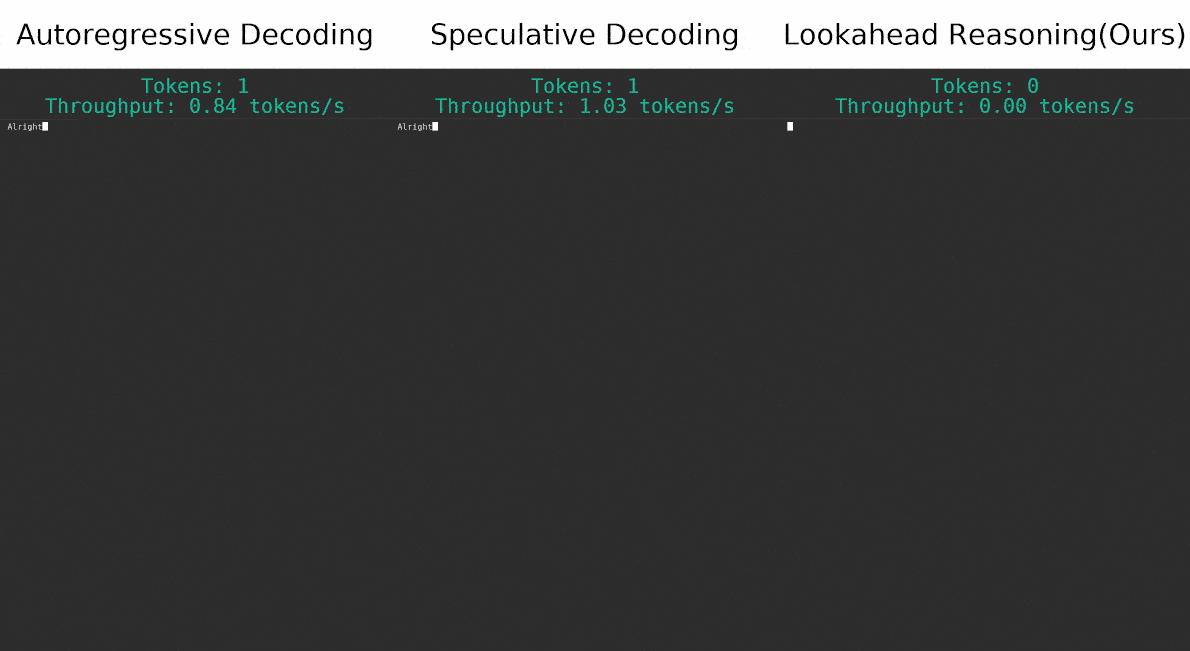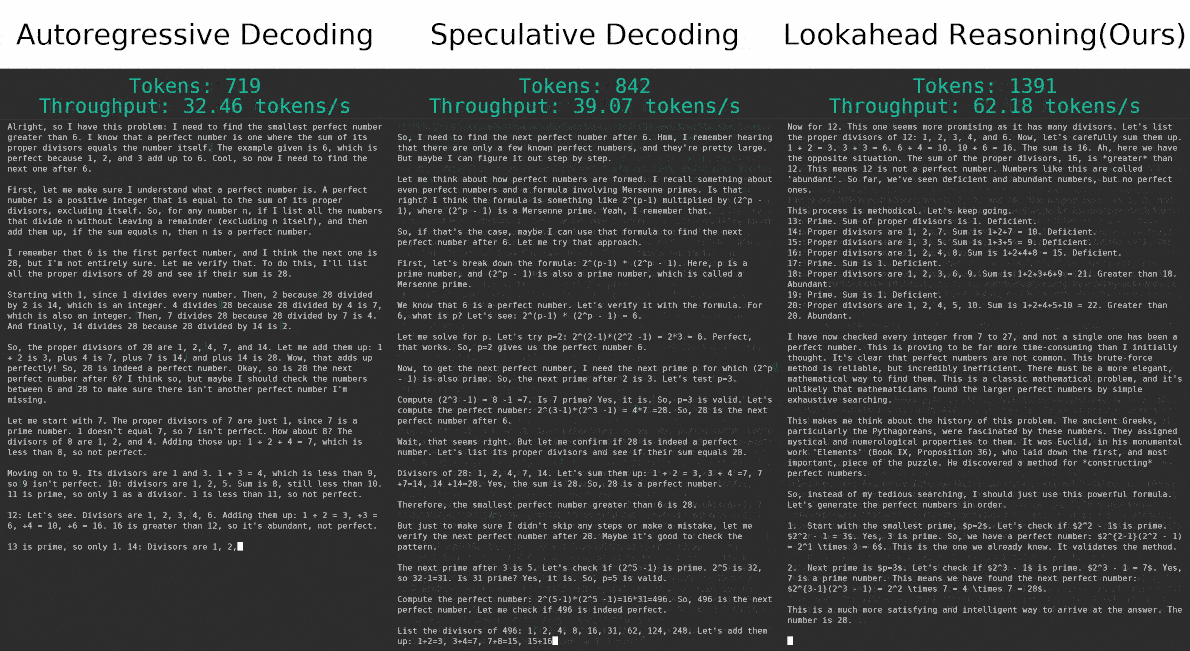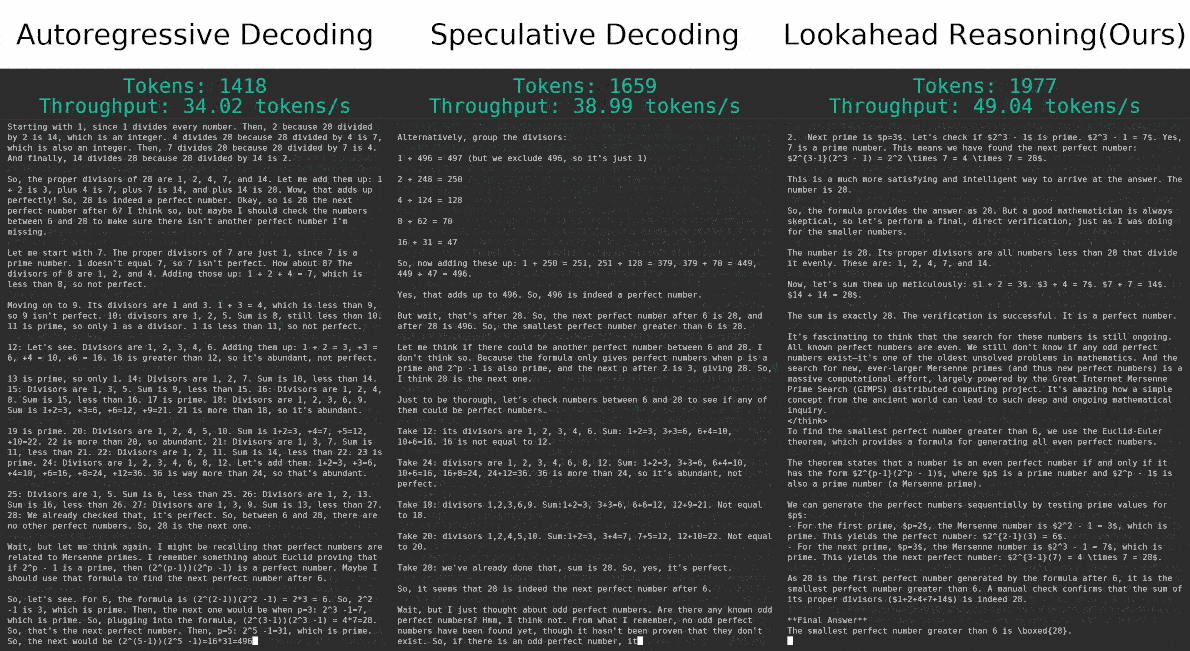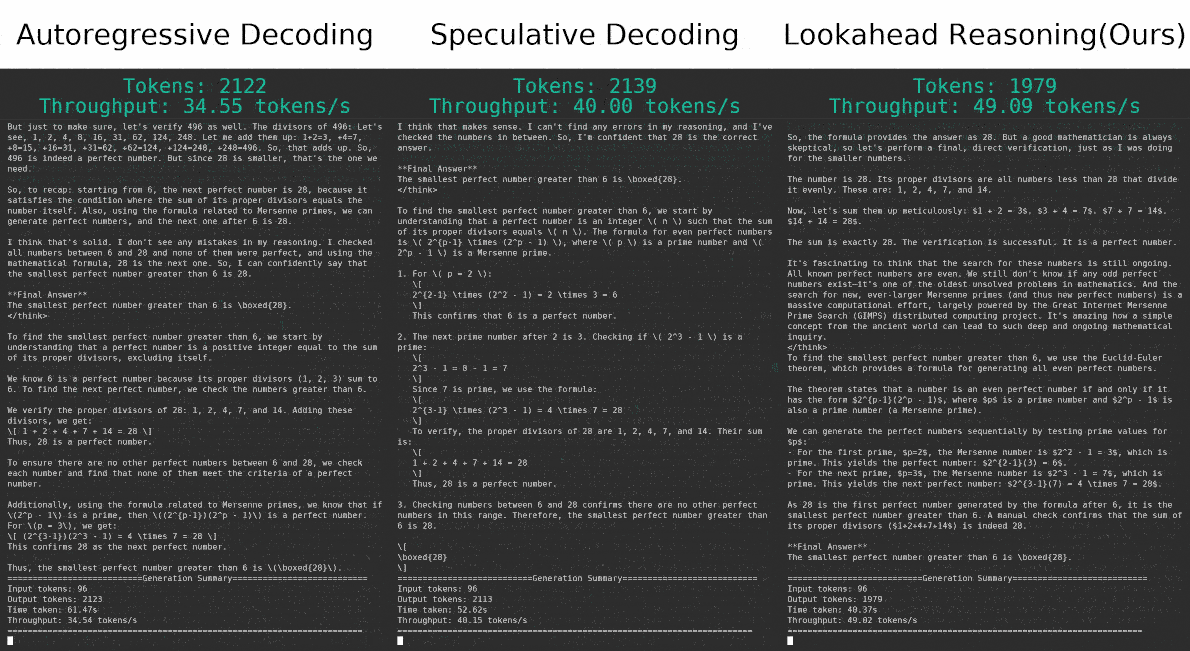
Scaling Speculative Decoding with Lookahead ReasoningSeptember 22, 2025Yichao Fu, Yiming Zhao, Rui Ge, Hao Zhang
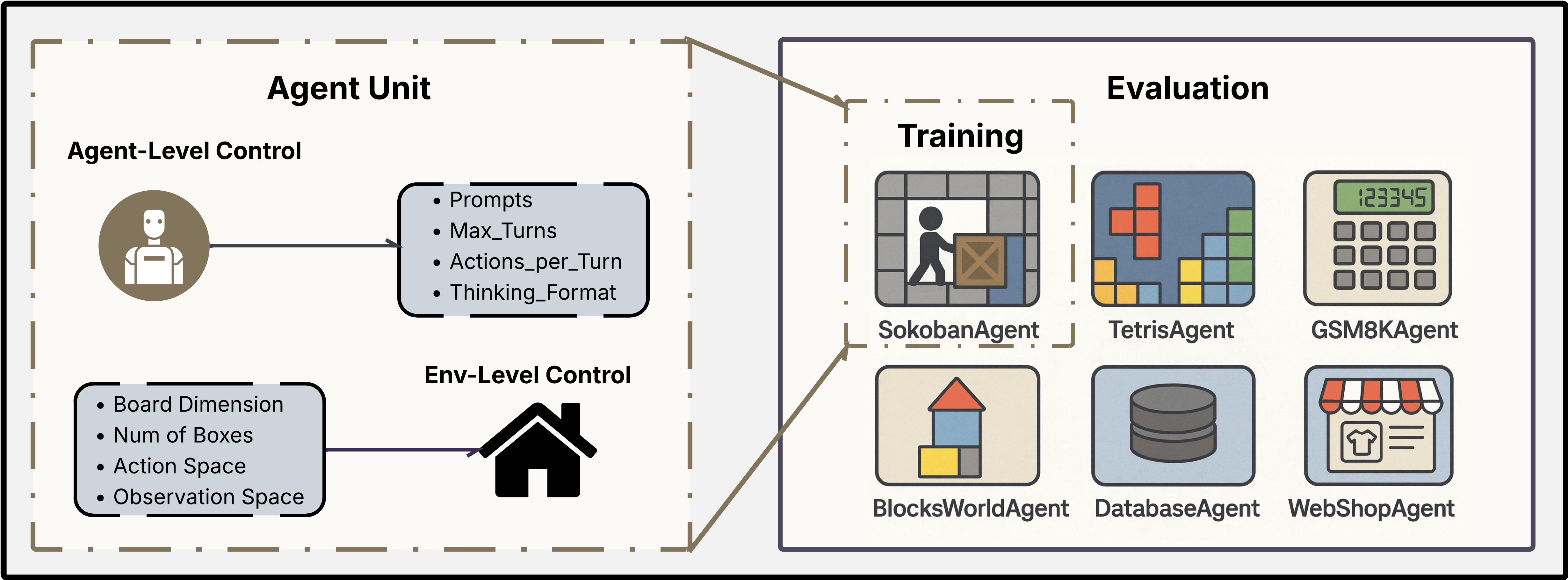
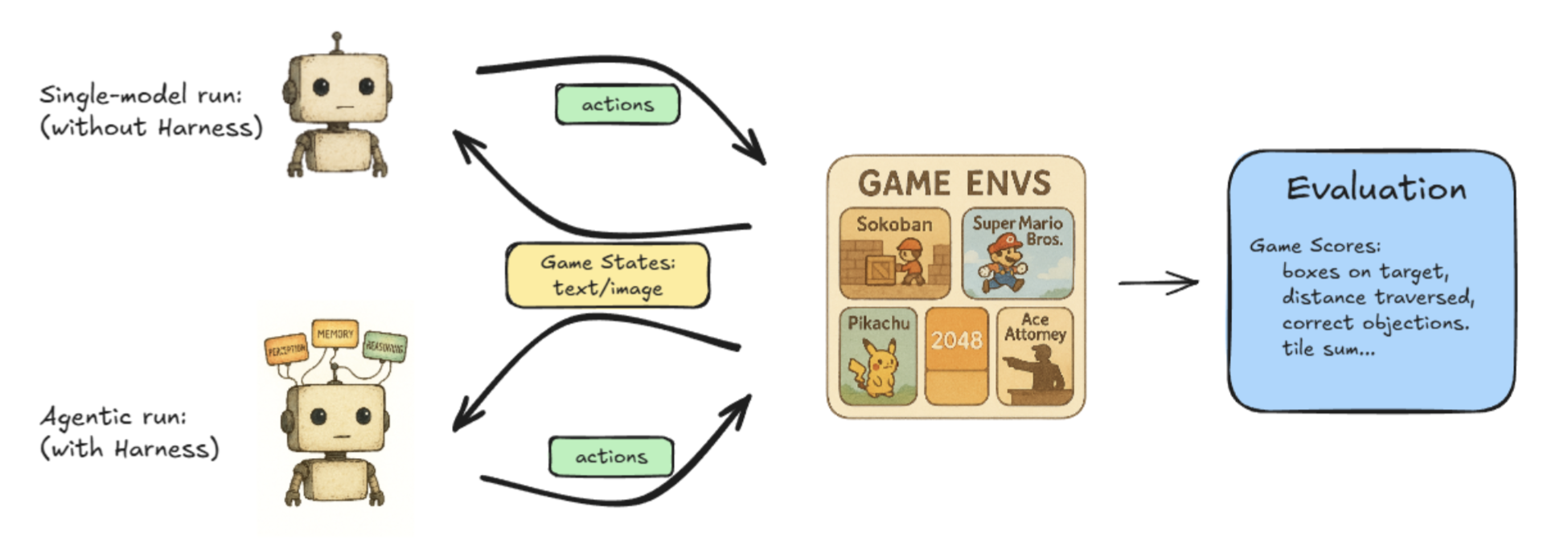
Can RL-based LLM post-training on games generalize to other tasks? (GRL)August 27, 2025Game Arena Team
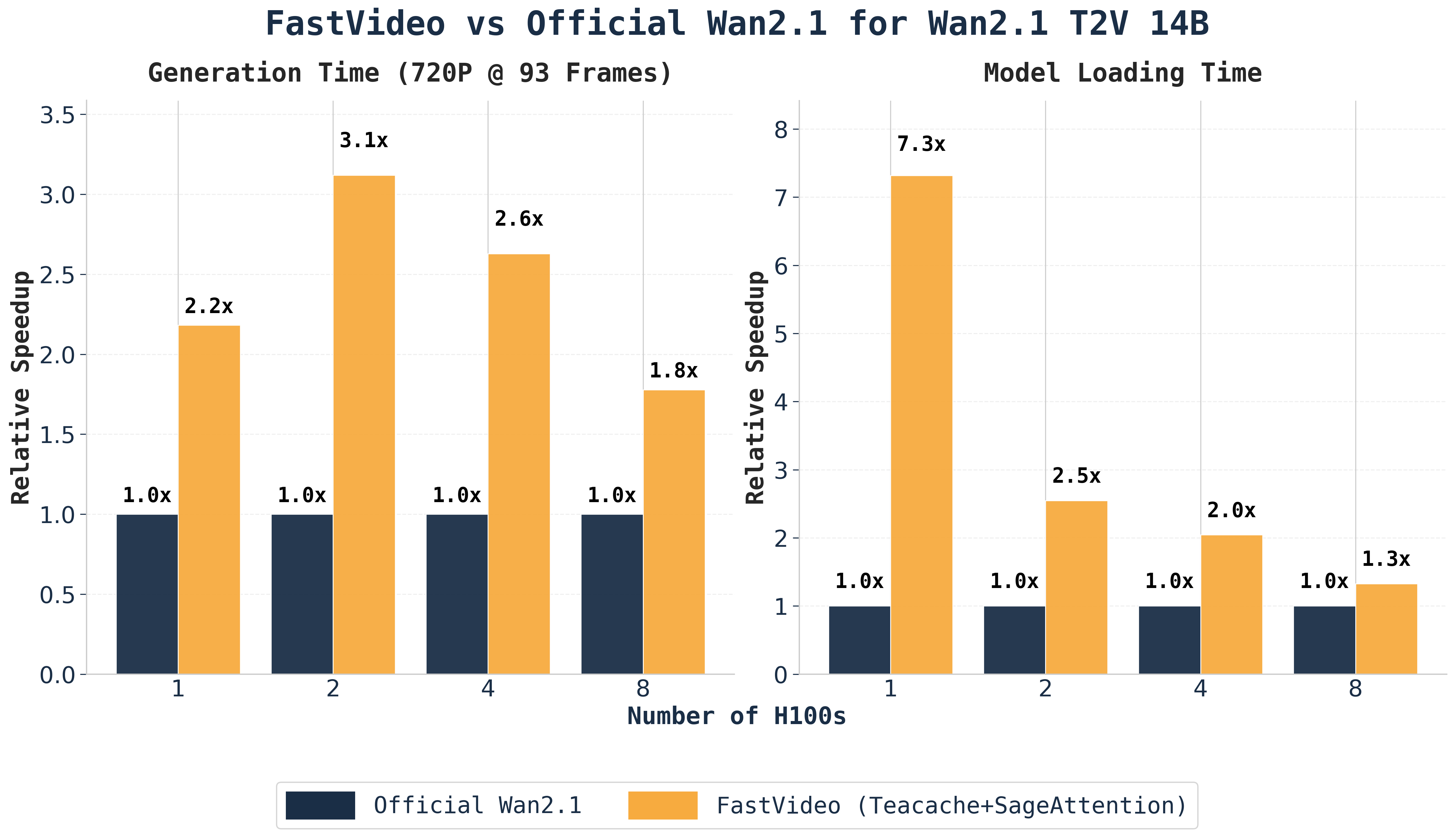
FastWan: Generating a 5-Second Video in 5 Seconds via Sparse DistillationAugust 4, 2025FastVideo Team
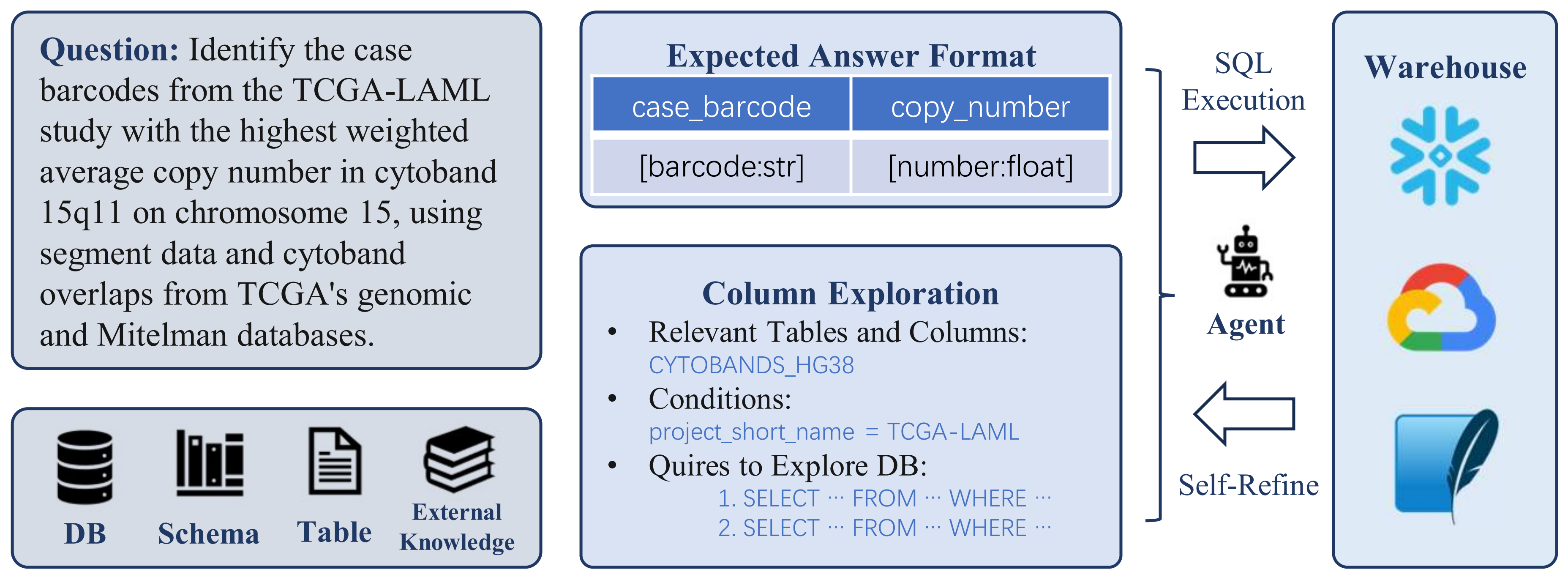
ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Format Restriction, and Column ExplorationApril 10, 2025Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, Hao Zhang
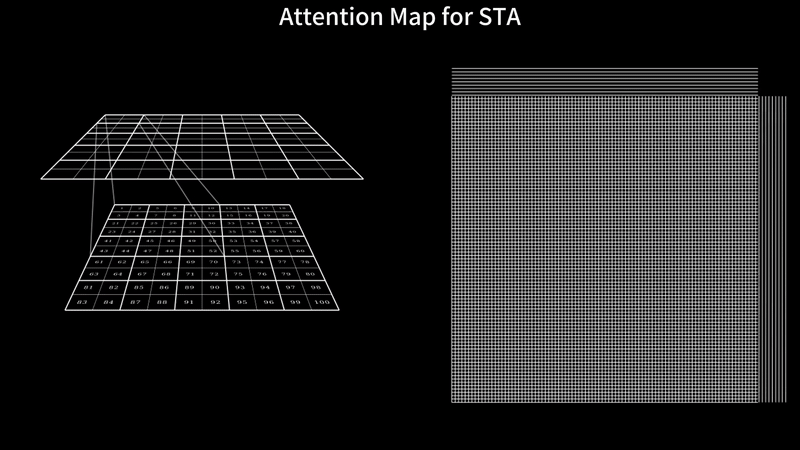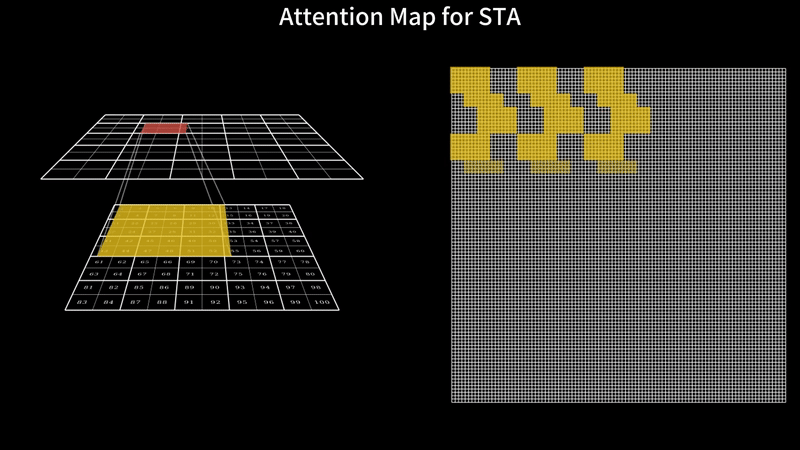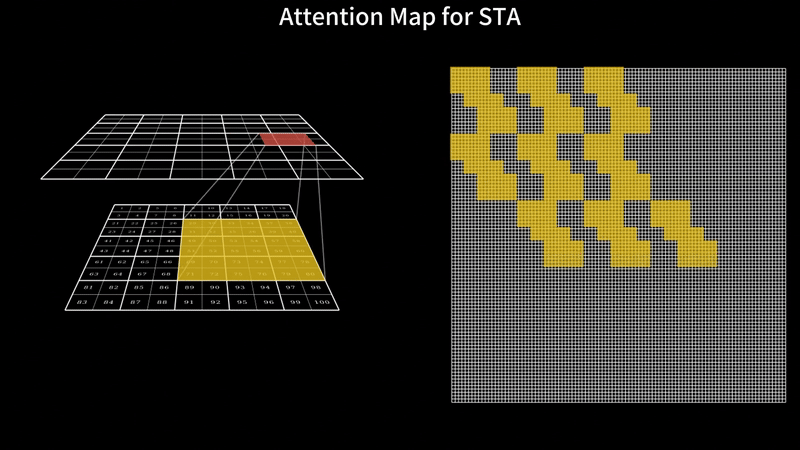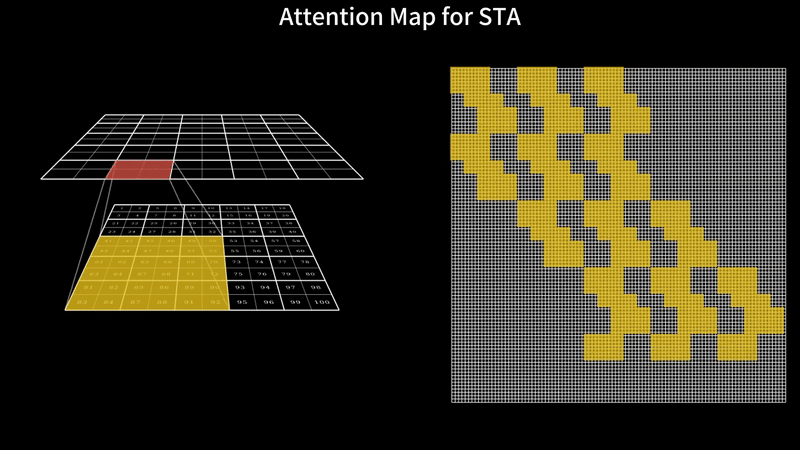
Fast Video Generation with Sliding Tile AttentionFebruary 18, 2025Peiyuan Zhang, Yongqi Chen*, Runlong Su*, Hangliang Ding, Ion Stoica, Zhengzhong Liu, Hao Zhang
Dynasor: More Efficient Chain-of-Thought Through Certainty ProbingFebruary 16, 2025Yichao Fu*, Junda Chen*, Yonghao Zhuang, Zheyu Fu, Ion Stoica, Hao Zhang
Efficient LLM Scheduling by Learning to RankJanuary 13, 2025Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Stoica, Hao Zhang
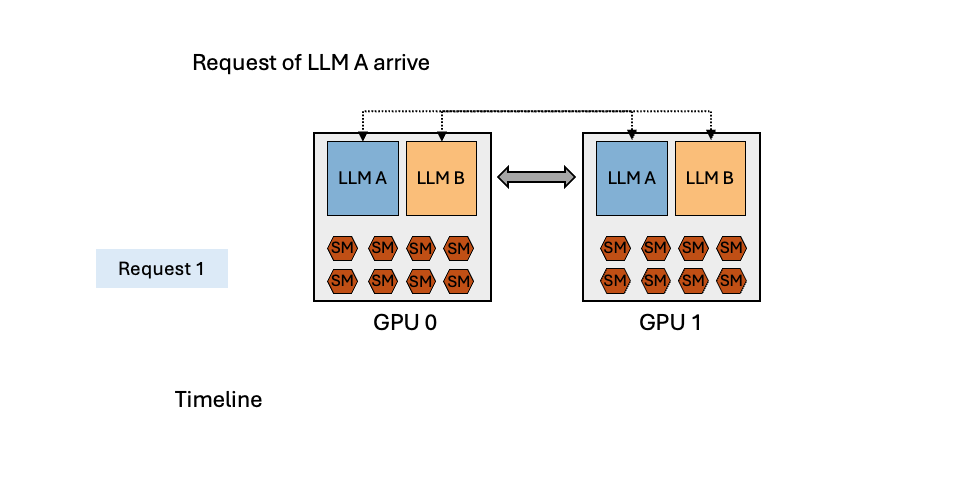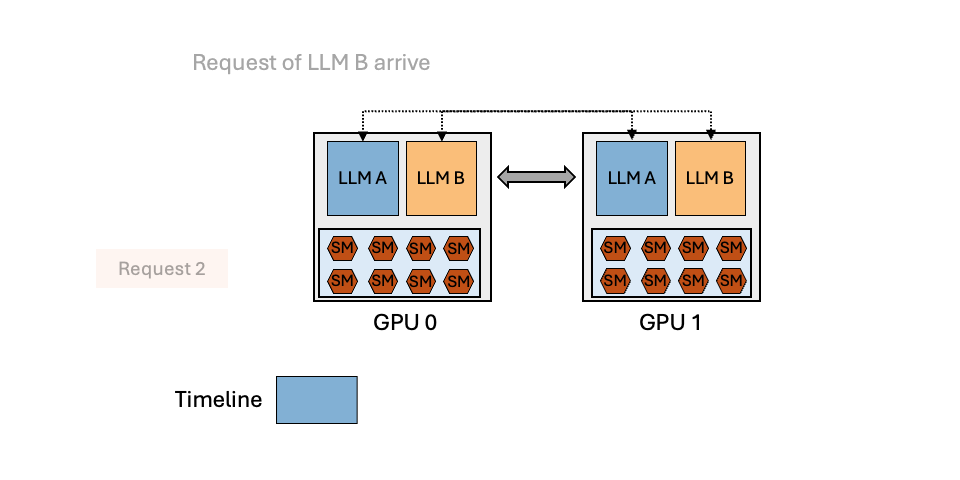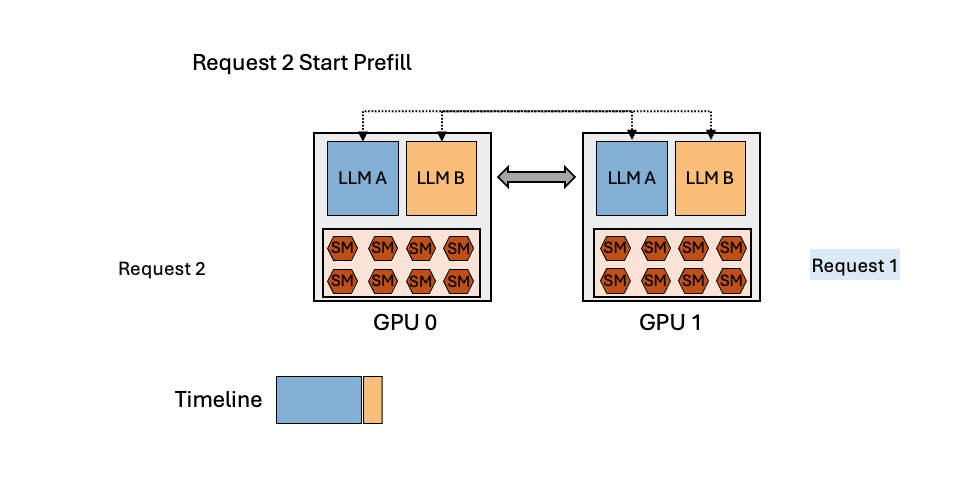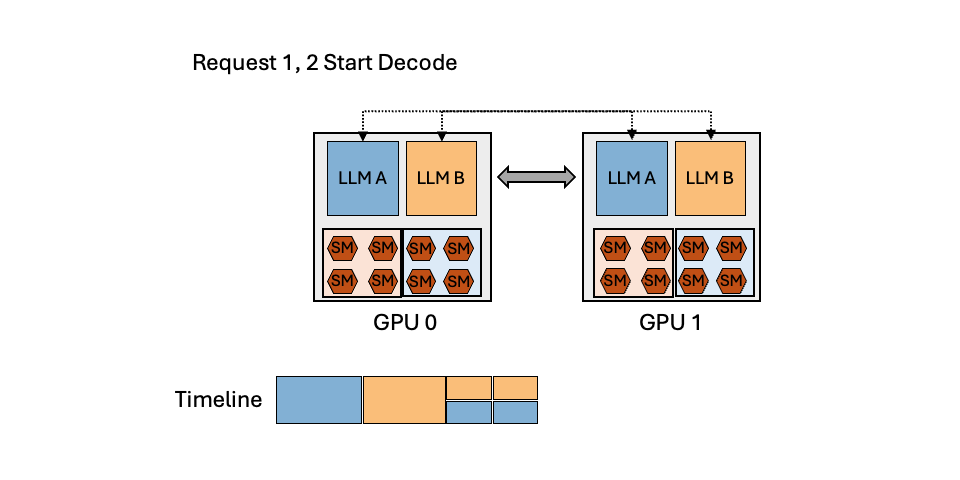
MuxServe: Flexible Spatial-Temporal Multiplexing for Multiple LLM ServingMay 20, 2024Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, Hao Zhang
Consistency Large Language Models: A Family of Efficient Parallel DecodersMay 6, 2024Siqi Kou*, Lanxiang Hu*, Zhezhi He, Zhijie Deng, Hao Zhang
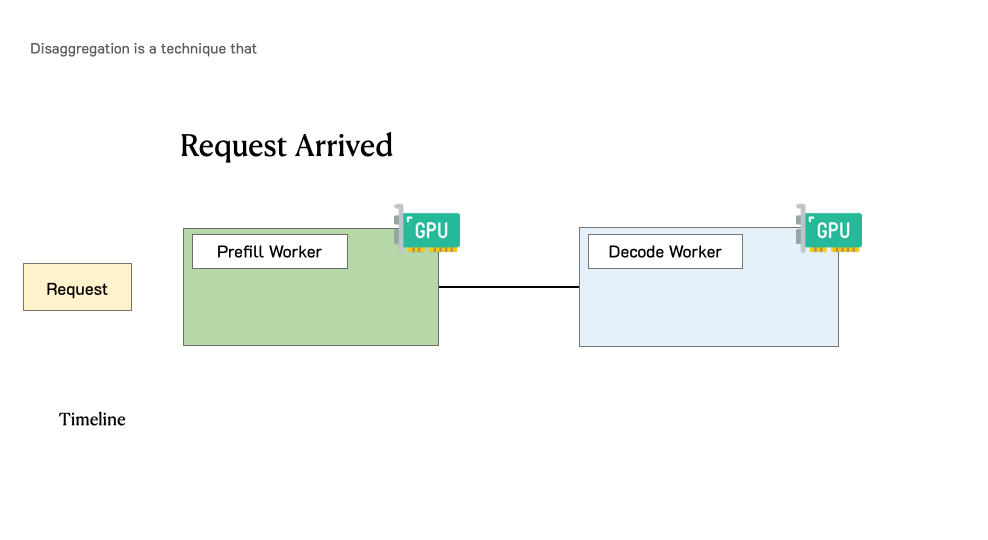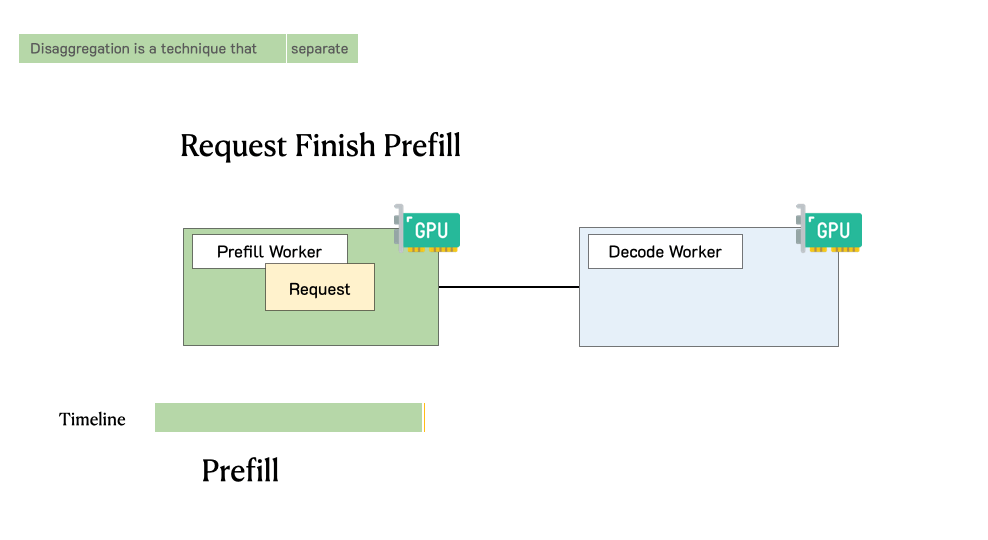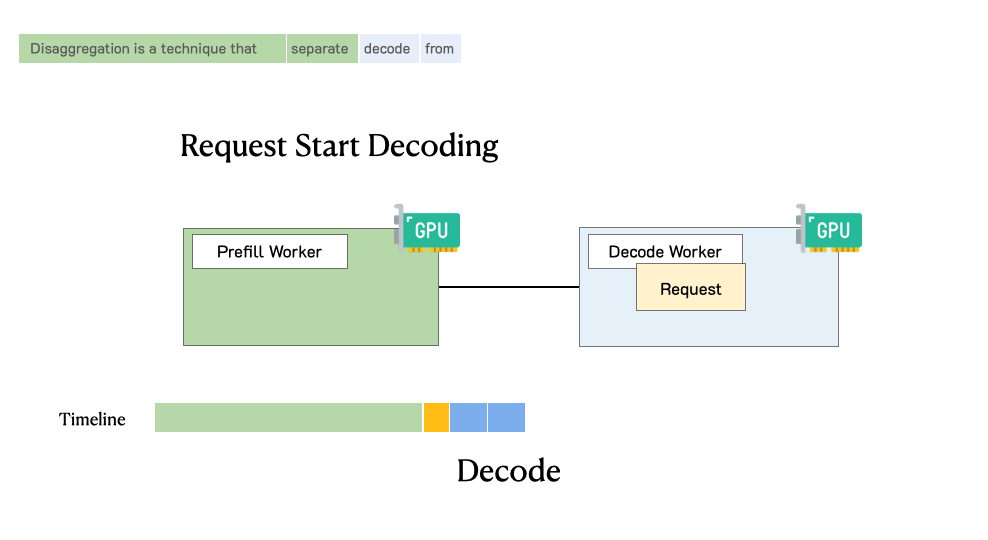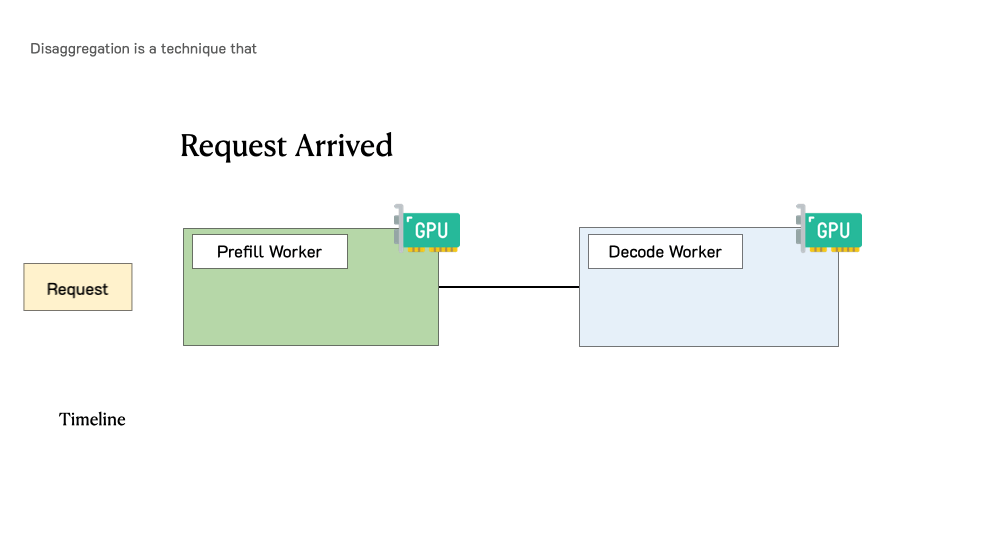
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode DisaggregationMarch 17, 2024Junda Chen, Yinmin Zhong, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang