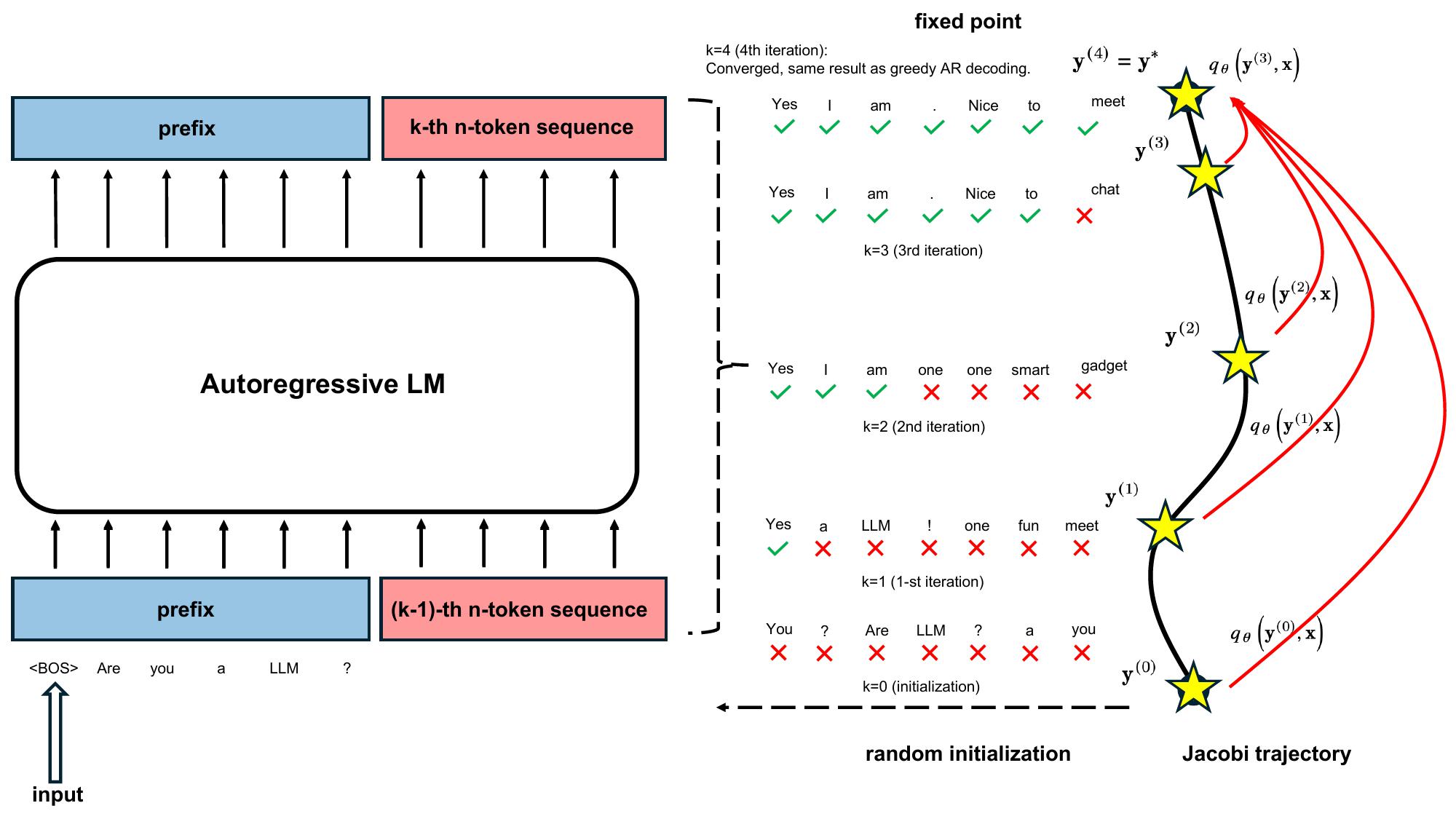
Consistency Large Language Models: A Family of Efficient Parallel DecodersMay 6, 2024Siqi Kou*, Lanxiang Hu*, Zhezhi He, Zhijie Deng, Hao Zhang
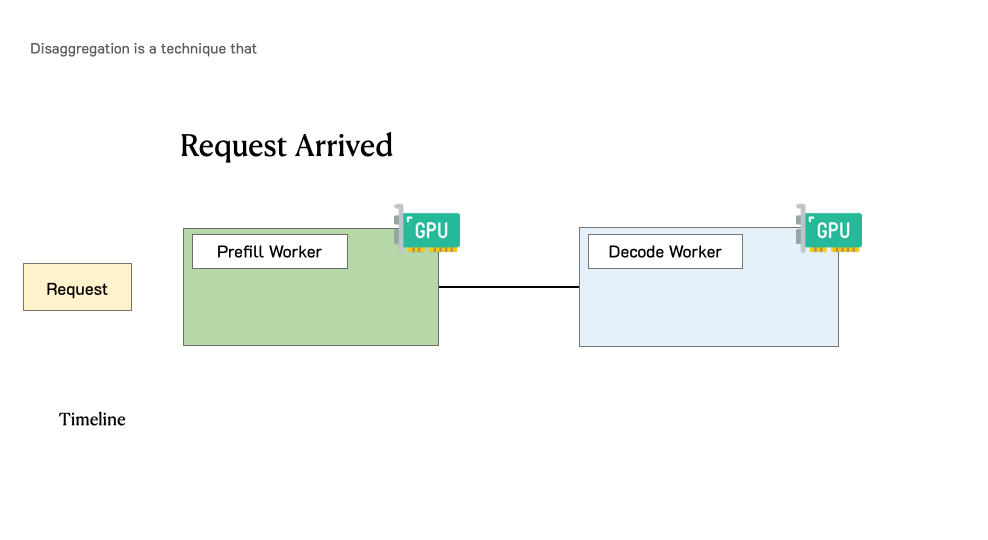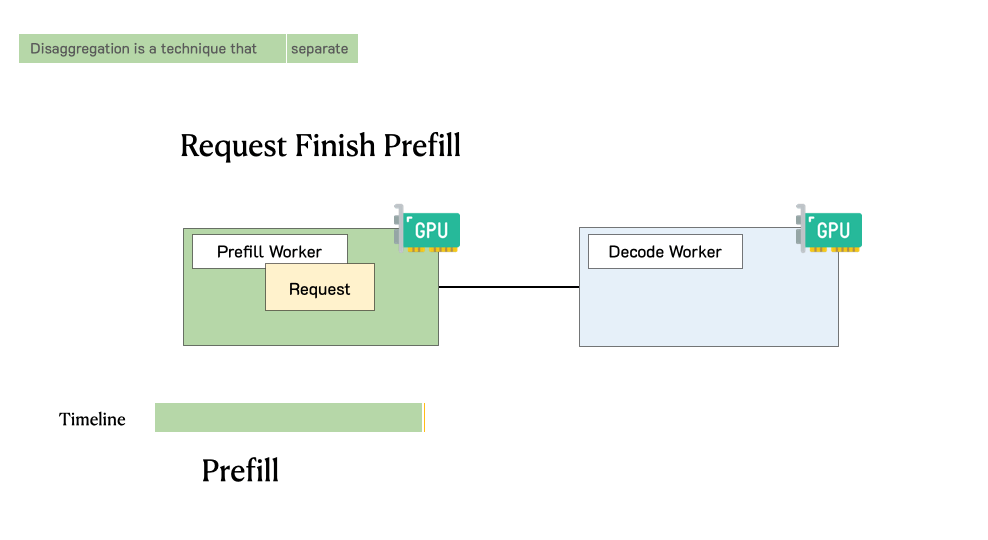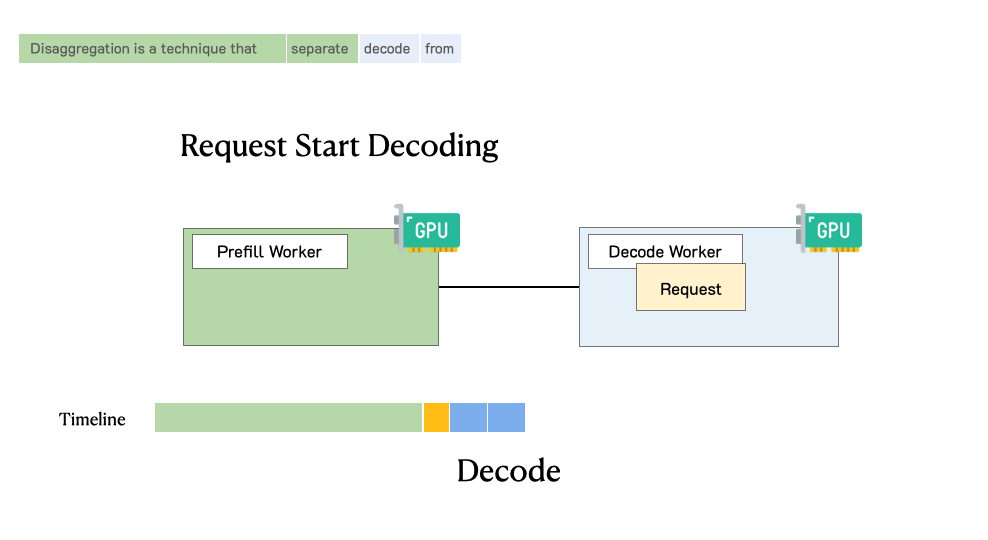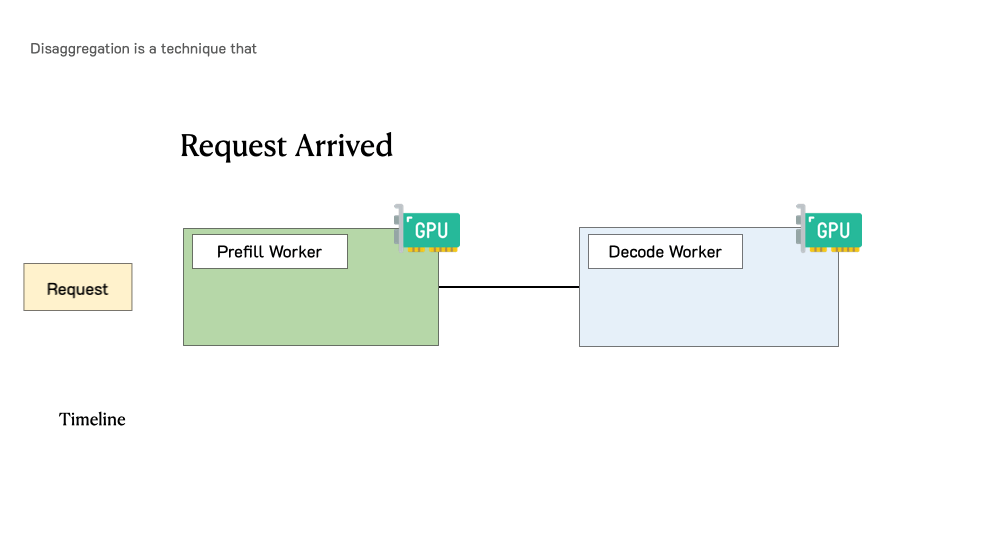
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode DisaggregationMarch 17, 2024Yinmin Zhong, Junda Chen, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang