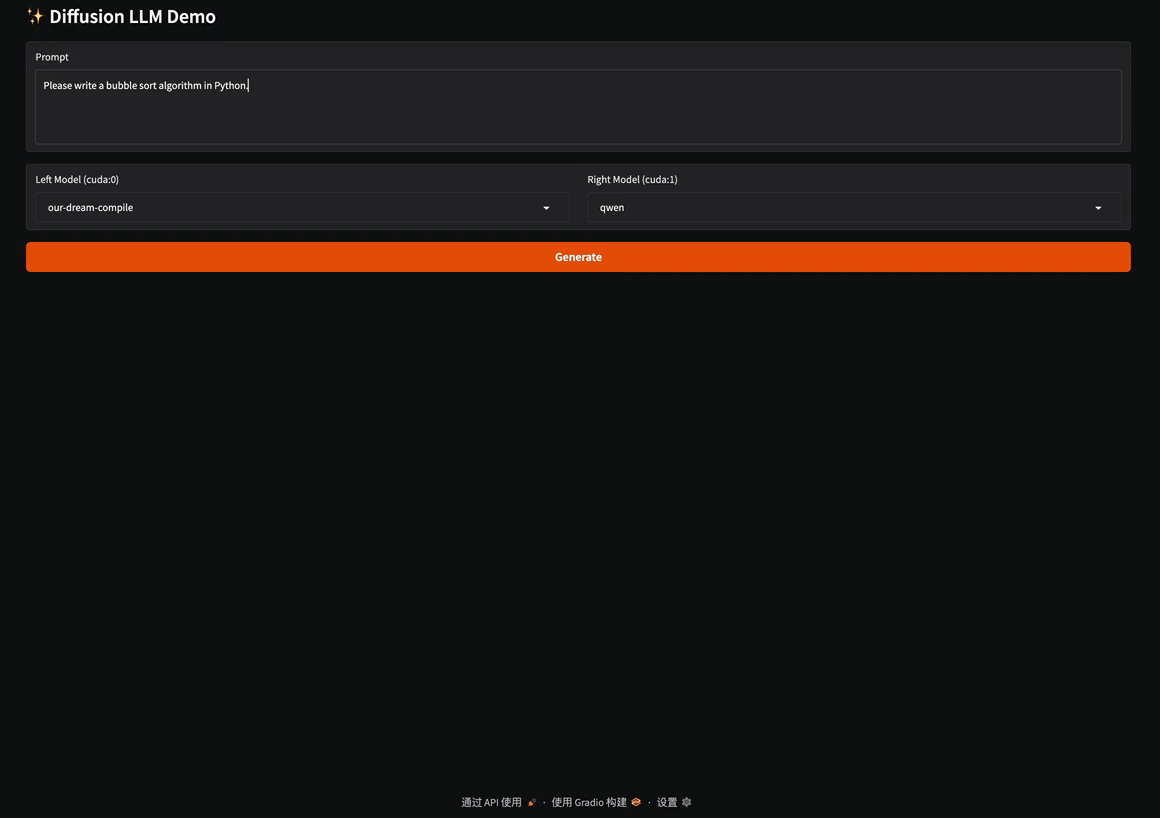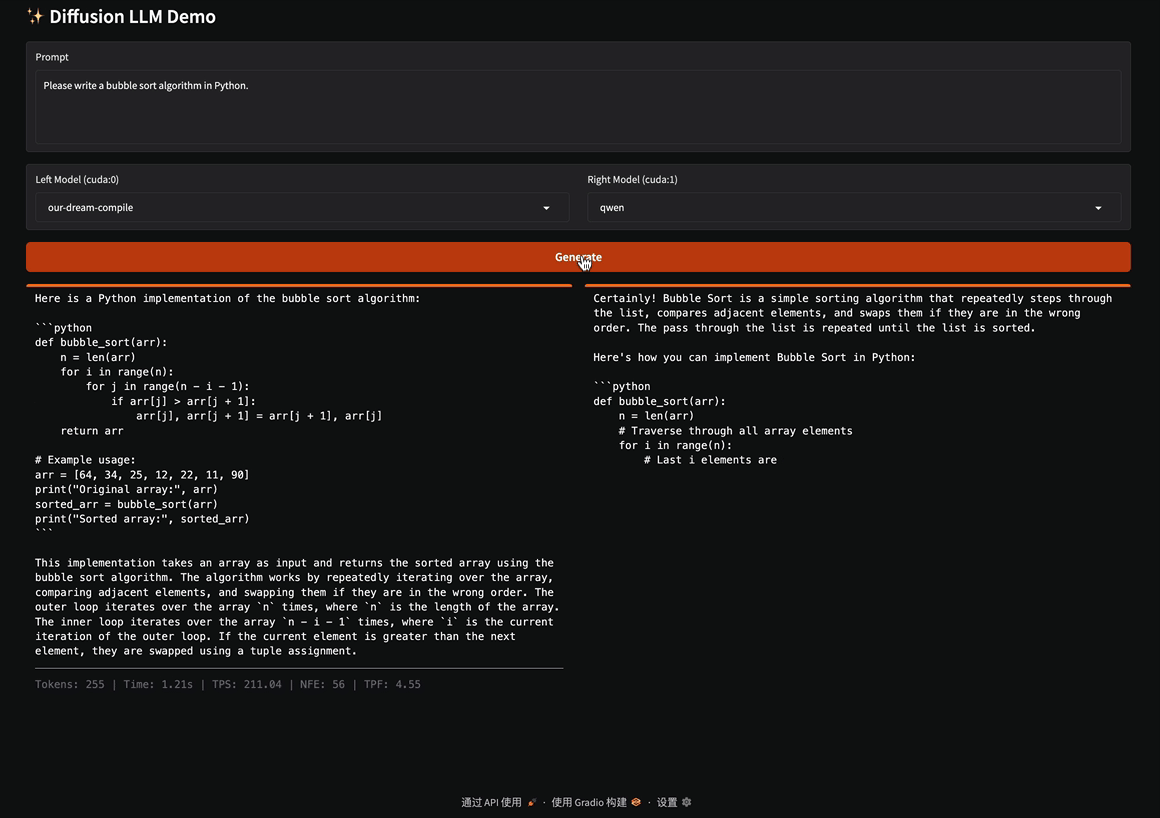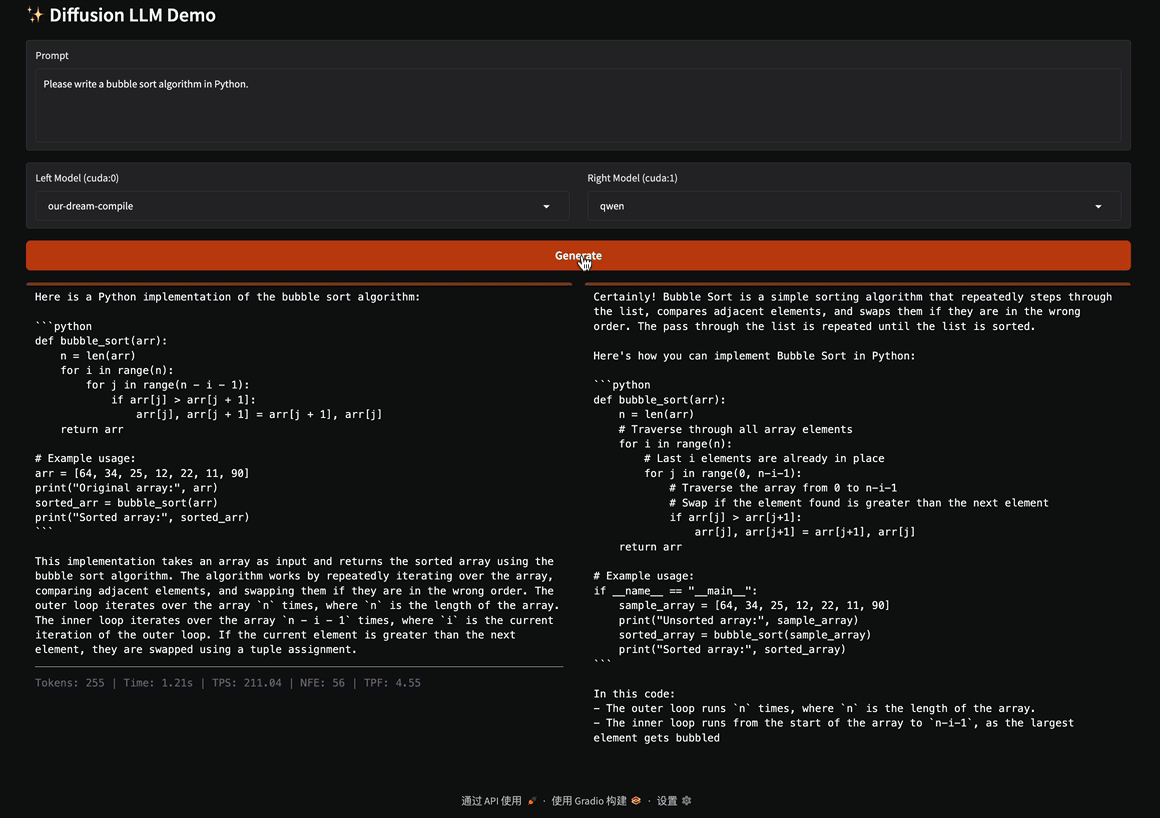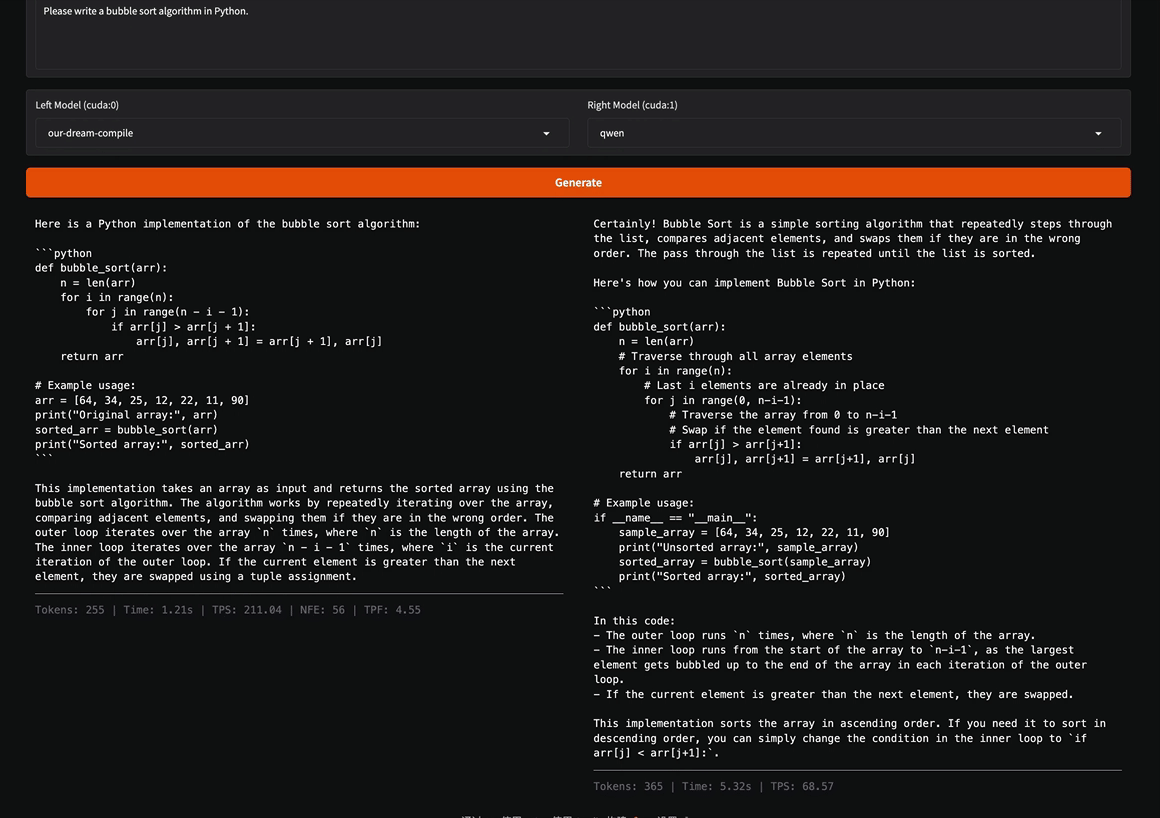

TL;DR: We introduce an ultra-fast diffusion-based language model framework, named d3LLM (pseuDo-Distillated Diffusion Large Language Model), which balances accuracy and parallel decoding through two key innovations: First, we propose a pseudo-trajectory based distillation method that leverages the teacher model’s decoding order, combined with curriculum strategies that progressively increase the noise level and window size. This stabilizes training and improves token-per-forward efficiency. Second, we employ an entropy-based multi-block decoding algorithm with KV-cache and refresh, enabling multiple future blocks to be decoded in parallel while preserving output quality, especially in long-context scenarios. Across LLaDA/Dream backbones on five benchmark datasets, d3LLM consistently achieves the highest AUP scores on 9 of 10 benchmarks and delivers substantial real-world speedups. It attains up to a 5× speedup over AR models (Qwen-2.5-7B-it) on an H100 GPU with minimal accuracy degradation.