TL;DR: LLM apps today have diverse latency requirements. For example, a chatbot may require a fast initial response (e.g., under 0.2 seconds) but moderate speed in decoding which only needs to match human reading speed, whereas code completion requires a fast end-to-end generation time for real-time code suggestions.
In this blog post, we show existing serving systems that optimize throughput are not optimal under latency criteria. We advocate using goodput, the number of completed requests per second adhering to the Service Level Objectives (SLOs), as an improved measure of LLM serving performance to account for both cost and user satisfaction.
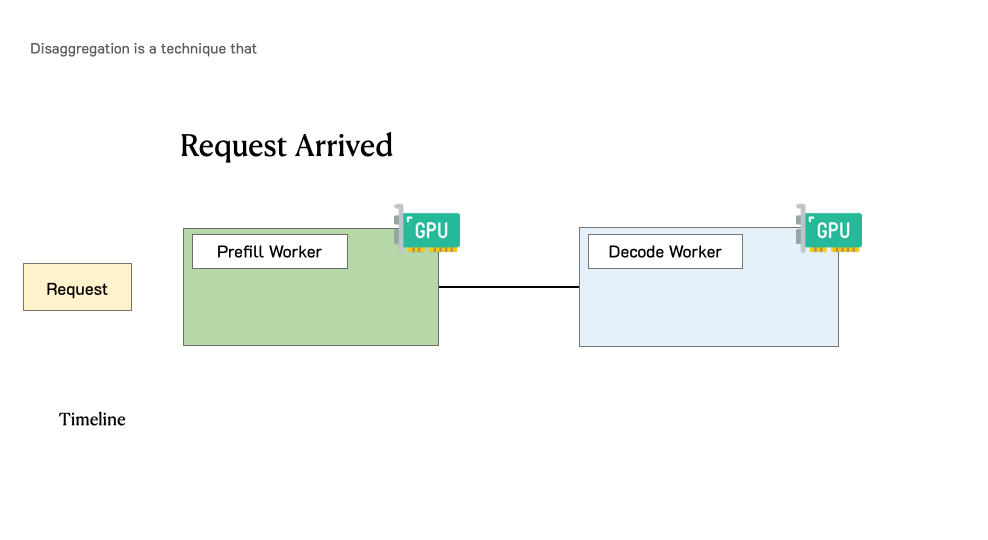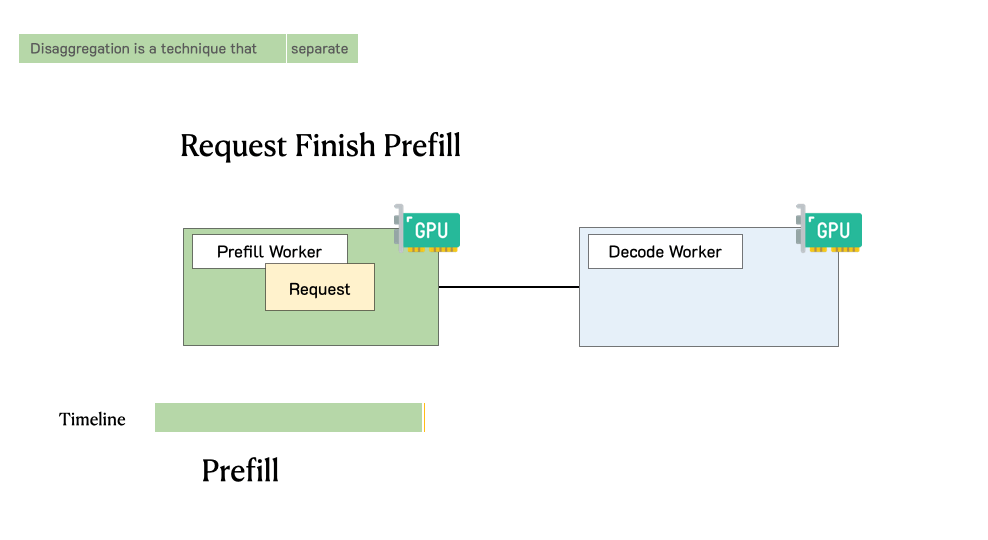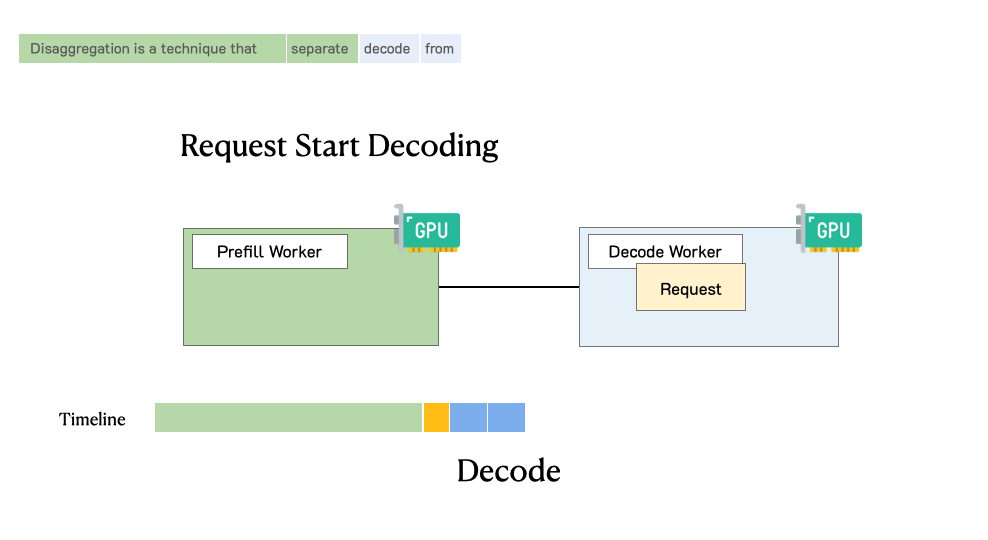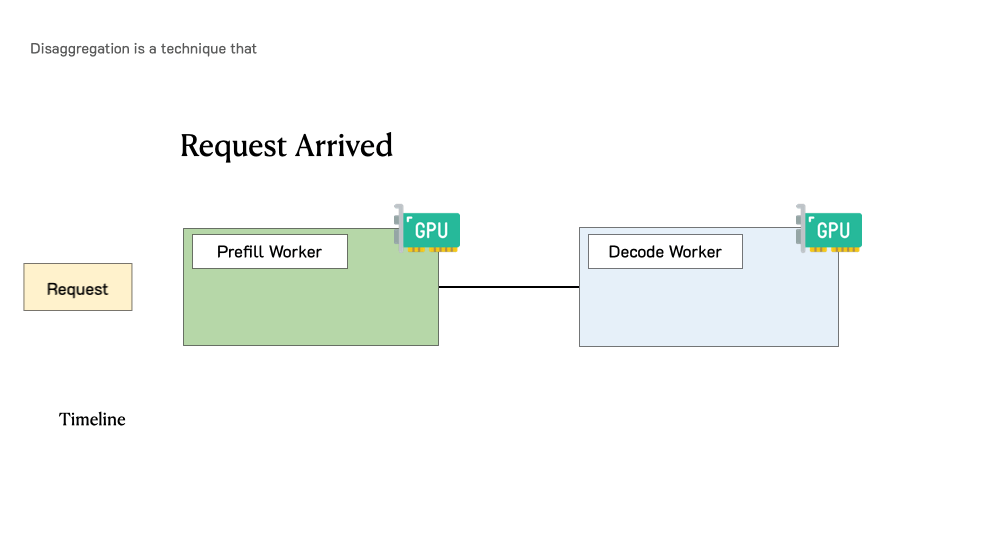
To optimize goodput, we introduce prefill-decode disaggregation, a.k.a. splitting prefill from decode into different GPUs. We also build a system prototype DistServe, which achieves up to 4.48x goodput or 10.2x tighter SLO compared to exiting state-of-the-art serving systems, while staying within tight latency constraints. We are integrating DistServe with vLLM to bring the technique to the community.